Managing Data
Services based on Amazon’s S3 protocol for object storage are ubiquitous and have many advantages in terms of cost, scalability, and ease of use. Unfortunately in a distributed environment, they also have a couple critical deficiencies:
- searching via stored metadata is inefficient and
- there are no facilities for federating S3 services from different providers.
The Nuvla data management model takes advantage of the positive aspects of S3, while providing global management of metadata for efficient search across providers.
WORM Model
The data management model follows Write-Once, Read-Mostly (WORM) semantics. This model:
- Optimises read access to data, simplifying access to the data via the underlying services and improving performance.
- Facilitates the replication of data objects, allowing “hot” data to be accessed efficiently on multiple providers.
- Improves the reproducibility of data analyses by providing unique identifiers for “versions” of data objects.
Applications can also read data directly from other sources as necessary. For example, an application can read streamed data directly from a sensor, something common at the edge of the hybrid computing platform.
Concretely, the implementation consists of three Nuvla resources:
data-object: This resource is a proxy for data stored in a bucket/object within S3 from a given provider. This resource manages the lifecycle of an S3 object, allowing easy upload and download of the data.data-record: This resource provides additional, user-specified metadata for an object. This allows rich, domain-specific metadata to be attached to objects and consequently, precise searching for relevant data objects.data-set: This resources defines dynamic collections ofdata-objectand/ordata-recordresources via filters. These can be defined by administrators, managers, or users.
Together, these provide a flexible data management framework, applicable to a
wide range of use cases. The usual (simplified) workflow consists of 1) creating
a data-object (and implicitly the S3 object), 2) optionally adding rich
metadata in a data-record object, and 3) finding (and using) the data-object
resources included in a data-set. The “using” element of the data-object in
the last step is facilitated by Nuvla in the form of binding of the data types
to the user applications that are capable of processing the data.
Data-Object Resources
The data-object resource allows users to create S3 objects on service
providers and to store simple metadata concerning those objects.
Creating
The following diagram provides an overview of the workflow for creating
a data-object resource.
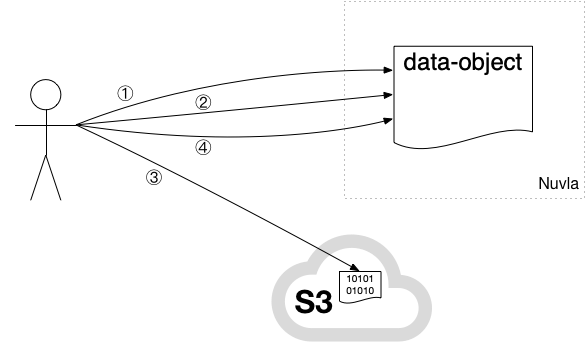
The workflow consists of the following steps:
-
Create data-object resource by providing bucket, object, and S3 credential.
-
Request pre-signed upload URL via “upload” action.
-
Use pre-signed upload URL to upload object contents to S3.
-
Mark object as “ready” (and read-only) via the “ready” action.
NOTE: if bucket does not exist it will be created as part of step 1. The object on S3 will be created when you explicitly upload the data to S3 in step 3.
Reading
The data can be consumed by others via the “download” action only when the object has been marked as “ready”. When the object is “ready” the object data can no longer be modified.
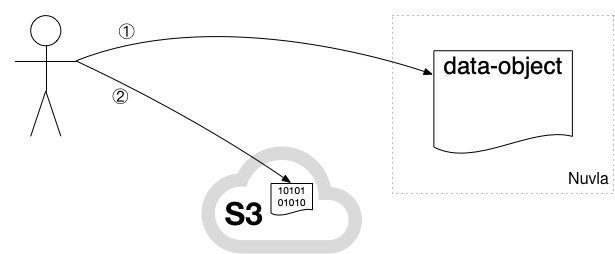
The workflow consists of the following steps:
-
Request pre-signed download URL via the “download” action.
-
Use pre-signed download URL to download object contents from S3.
NOTE: only the pre-signed URL is generated by the Nuvla server. The heavyweight access to the data itself happens directly between the client and the provider’s S3. This ensures that the data transfer uses the highest possible bandwidth.
Deleting
The data object and underlying S3 object can be deleted.
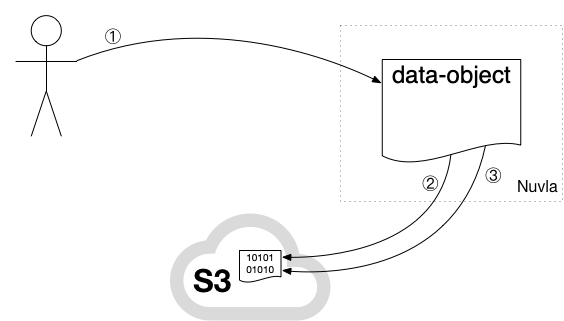
The workflow consists of the following steps:
-
Request to delete the data-object resource via the HTTP DELETE request.
-
Server verifies access and deletes the object from S3.
-
Server also deletes the bucket if it is empty.
Once the object is deleted, it is no longer accessible either through Nuvla or the underlying S3.
Data-Record Resources
The data-record resources provide rich metadata for data objects, either
created through data-object resources in Nuvla or externally.
These resources are simply JSON documents that are searched, created, updated, and deleted via the standard SCRUD patterns of the API.
Aside from a small set of predefined keys, the schema for the
data-record resources is open, allowing users, managers, and administrators to
attach their own domain-specific metadata to a data object.
An example data-record resource looks like the following:
{
"id": "data-record/1e48a9d1-9a26-453c-b392-13e179fd53b4",
"resource-type": "data-record",
"name": "data-object-1",
"description": "data-object-1 description",
"created": "2019-03-14T16:16:04.768Z",
"updated": "2019-03-14T16:16:04.768Z",
"infrastructure-service": "infrastructure-service/b3ec10fb-086e-42f2-8fdb-a215f6ef2089",
"resource:protocol": "NFS",
"resource:object": "data-object/6a1be147871c7a542ccd0047b5a03b20"
"data:bucket": "new-bucket-for-tests",
"data:object": "new-object-for-tests",
"data:content-type": "text/plain",
"data:bytes": 1024,
"data:timestamp": "2019-03-14T16:16:04Z",
"data:nfsIP": "159.100.242.78",
"data:nfsDevice": "/nfs-root",
"data:protocols": [
"tcp+nfs"
],
"gnss:mission": "random"
}
WARNING: Although the schema is open, all the key prefixes must be defined as
data-record-key-prefixresources. Having prefixed attributes avoids collisions between domains. Only the Nuvla administrator can define these prefixes.
NOTE: It is strongly recommended providing a
data-record-keyresource for each domain-specific key. These resources provide semantic information about the key to help humans provide the right information.
Data-Set Resources
The data-set resources define dynamic collections of data-object
and/or data-record resources based on filters over those resources.
The data-set resource can also identify appropriate applications
based on file types or other criteria.
These resources are simply JSON documents that are searched, created, updated, and deleted via the standard SCRUD patterns of the API.
An example data-set resource looks like the following:
{
"id": "data-set/ca96c2c1-317f-40cf-b9f3-8ebd0d87e7a2",
"resource-type": "data-set",
"name": "GREAT (CLK)",
"description": "GREAT (CLK) data at ESA",
"created": "2019-03-14T16:16:03.406Z",
"updated": "2019-03-14T16:16:03.406Z",
"module-filter": "data-accept-content-types='application/x-clk'",
"data-record-filter": "gnss:mission='great' and data:contentType='application/x-clk'"
}
This data-set selects only data-record resources related to the
GNSS mission “great” and have a content type of
application/x-clk. The data-set also identifies appropriate
applications based on this content type via the module-filter value.
Any user can define their own data sets and share those definitions with others by setting an appropriate ACL.